
GSR-GNN: Training Acceleration and Memory-Saving Framework of Deep GNNs on Circuit Graph
Published in ACM/IEEE Design Automation Conference (DAC), 2026
Abstract
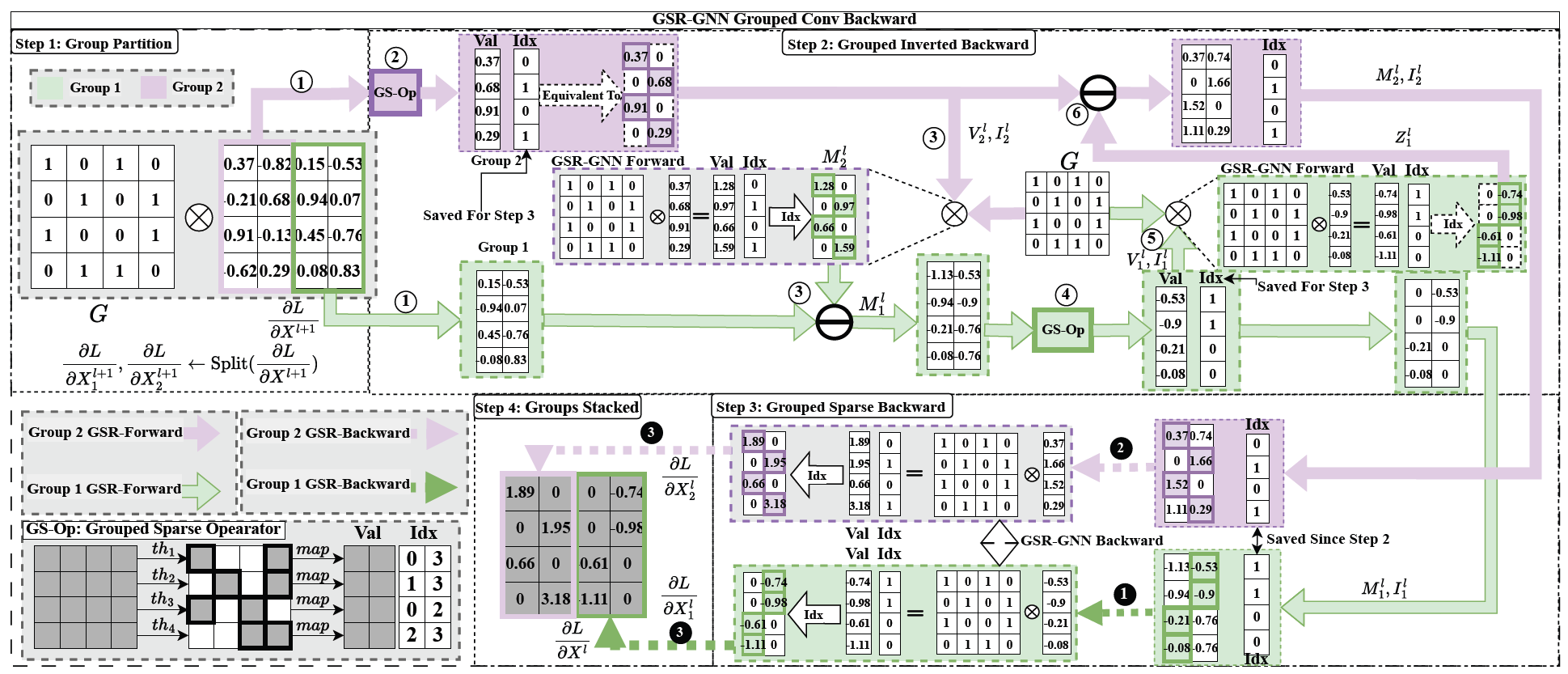
Graph neural networks (GNNs) show strong promise for circuit analysis, but scaling to modern large-scale circuit graphs is limited by GPU memory and training cost, especially for deep models. We propose Grouped-Sparse-Reversible GNN (GSR-GNN), which enables training GNNs with up to hundreds of layers while reducing both compute and memory overhead. GSR-GNN integrates reversible residual modules with a group-wise sparse nonlinear operator that compresses node embeddings without sacrificing task-relevant information, and employs an optimized execution pipeline to eliminate fragmented activation storage and reduce data movement. On sampled circuit graphs, GSR-GNN achieves up to 87.2% peak memory reduction and over 30x training speedup with negligible degradation in correlation-based quality metrics, making deep GNNs practical for large-scale EDA workloads.
Key Contributions
- Grouped-Sparse-Reversible GNN (GSR-GNN), a high-speed and memory-efficient domain-specific deep GNN framework
- Reversible residual structure with embedding compression during both forward and backward passes
- Optimized memory management workflow achieving over 90% memory utilization improvement
Authors
Yuebo Luo, Shiyang Li, Yifei Feng, Vishal Kancharla, Shaoyi Huang, Caiwen Ding
In Proceedings of the 63rd ACM/IEEE Design Automation Conference (DAC ‘26), San Francisco, CA, USA.
Recommended citation: Y. Luo, S. Li, Y. Feng, V. Kancharla, S. Huang, C. Ding. "GSR-GNN: Training Acceleration and Memory-Saving Framework of Deep GNNs on Circuit Graph." In Proceedings of the 63rd ACM/IEEE Design Automation Conference (DAC '26), 2026.
Download Paper